
Self-Rewarding Language Model
Exploring the Future of AI Training with Self-Rewarding LLM


In this #AI_Explained blog post, I will introduce a new method for training large language models (LLMs) that can learn from their own feedback and improve their abilities over time. The method is called Self-Rewarding Language Models (SRLLMs), and it was proposed by researchers from Meta and NYU in a recent paper.
Why do LLMs need feedback?
LLMs are powerful neural networks that can generate natural language for various tasks, such as answering questions, writing essays, or creating stories. They are usually pre-trained on large amounts of text data and then fine-tuned on specific tasks using human-annotated examples.
However, there are some limitations to this approach.
First, human-annotated examples are costly and scarce, and may not cover all the possible scenarios that the LLM may encounter. Second, human-annotated examples may also be biased or noisy, and may not reflect the true preferences or expectations of the users. Third, once the LLM is fine-tuned, it may not be able to adapt or improve further based on new feedback or data.
To overcome these limitations, researchers have proposed various methods to train LLMs using feedback from humans or other sources, such as web search results, external knowledge bases, or other LLMs. These methods aim to align the LLM with the desired behavior or objective and to make it more helpful, harmless, and robust.
However, these methods also have some drawbacks. For example, human feedback may be slow, inconsistent, or unreliable, and may not provide enough signal for the LLM to learn effectively. External sources may also be incomplete, outdated, or inaccurate, and may not match the LLM’s domain or style. Moreover, these methods often rely on a separate reward model, which is a function that assigns a numerical score to the LLM’s output based on the feedback. The reward model may be fixed or frozen, and may not be able to improve or update along with the LLM.
What are SRLLMs and how do they work?
SRLLMs are a novel method that addresses these challenges by enabling the LLM to generate and evaluate its own feedback, and to use it for self-training. The idea is to develop an agent that has two skills simultaneously:
Instruction following: given a prompt that describes a user request, the ability to generate a high-quality, helpful (and harmless) response.
Self-instruction creation: the ability to generate and evaluate new instruction following examples to add to its own training set.
These skills are used so that the LLM can perform self-alignment, i.e., they are the components used to iteratively train itself using AI Feedback (AIF).
The key innovation of SRLLMs is that they use the LLM itself as the reward model, rather than a separate or fixed one. This is done by using a technique called LLM-as-a-Judge, which is a way of formulating the evaluation of responses as an instruction following a task. For example, the LLM can be asked to review a response and give a score based on some criteria, such as relevance, completeness, clarity, or safety. This way, the LLM can provide its own rewards for its own generations, and also learn to improve its evaluation ability over time.

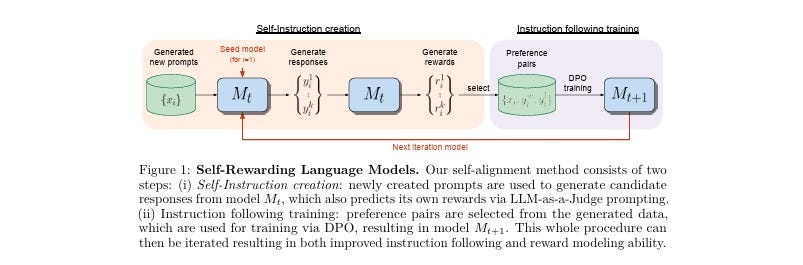
The overall procedure of SRLLMs is an iterative one, which proceeds by building a series of models, with the aim that each improves over the last. The procedure consists of the following steps:
Initialization: The LLM is initialized with a base pre-trained model, and a small amount of human-annotated seed data for instruction following and evaluation tasks. The LLM is fine-tuned on this seed data using supervised learning.
Self-instruction creation: Using the fine-tuned LLM, new prompts are generated using few-shot prompting, which is a way of sampling prompts from the original seed data. For each prompt, multiple candidate responses are generated using sampling and then evaluated by the LLM-as-a-Judge. The evaluations are used to construct preference pairs, which are pairs of responses with different scores for the same prompt.
Instruction following training: Using the preference pairs, the LLM is trained using Direct Preference Optimization (DPO), which is a way of optimizing the LLM to generate responses that are preferred over others. This results in a new LLM that is better at both instruction following and evaluation tasks.
Iteration: The whole procedure can be repeated with the new LLM, generating and evaluating new prompts and responses, and training on new preference pairs. This can lead to a virtuous cycle of self-improvement, where the LLM becomes better at both generating and judging its own feedback.
What are the benefits and challenges of SRLLMs?
SRLLMs have several advantages over existing methods for training LLMs with feedback. First, they do not rely on human feedback, which can be costly, scarce, or unreliable. Second, they do not depend on external sources, which can be incomplete, outdated, or inaccurate. Third, they do not use a separate or fixed reward model, which can be a bottleneck or a source of error. Instead, they use the LLM itself as the reward model, which can be more consistent, adaptive, and scalable.
However, SRLLMs also face some challenges and limitations. For example, they still require a small amount of human-annotated seed data to initialize the LLM and to provide some guidance and supervision. Moreover, they may not be able to capture all the nuances and subtleties of human preferences or expectations and may miss some important aspects of the tasks or domains. Furthermore, they may be prone to overfitting, reward hacking, or self-reinforcing biases, and may not be able to correct or prevent them without external feedback or intervention.
Therefore, SRLLMs are not a silver bullet, but rather a promising direction for future research and development. They open the door to the possibility of creating LLMs that can continually improve in both axes of instruction following and evaluation, and that can potentially achieve superhuman performance and alignment.
References:
Weizhe Yuan, Richard Yuanzhe Pang, Kyunghyun Cho, Sainbayar Sukhbaatar, Jing Xu, and Jason Weston. Self-Rewarding Language Models. arXiv preprint arXiv:2401.10020, 2024.