
NeuralByte's weekly AI rundown - 18th February
Two major news this week. OpenAI's video generator Sora destroyed internet with it's jaw breaking videos and Google Gemini 1.5 which can work with 44 minites long movie.

Greetings fellow AI enthusiasts!
This time I will concentrate more on two major news from Google and OpenAI. I had quite a busy week so this maybe won’t be as long as usual. But I hope you’ll like it.

Dear subscribers,
Thanks for reading my newsletter and supporting my work. I have more AI content to share with you soon. Everything is free for now, but if you like my work, please consider becoming a paid subscriber. This will help me create more and better content for you.
Now, let's dive into the AI rundown to keep you in the loop on the latest happenings:
✨ OpenAI’s Sora: A breakthrough in video generation and simulation
💵 Google Gemini 1.5: A Breakthrough in Long-Context Understanding
🤖 Chat with RTX: A New Way to Personalize Your AI Chatbot
🏷️ OpenAI CEO Sam Altman talks about GPT-5, the next generation of AI chatbot
📰 How Ukraine Became an AI War Lab for Western Tech Companies
🕵️ ChatGPT’s New Memory Feature: A Game-Changer for Language Models
And more!
OpenAI’s Sora: A breakthrough in video generation and simulation
Last week, OpenAI revealed its first video-generating model, Sora, and stunned the AI community with its photorealistic and imaginative videos. Sora can produce high-fidelity videos of up to a minute long, based on text prompts or existing videos. Sora can also simulate digital worlds, such as video games, and interact with them in real time.
Sora is a text-conditional diffusion model, which means it generates videos by gradually refining random noise into realistic images, conditioned on a text description. Sora can handle videos and images of variable durations, resolutions, and aspect ratios, making it a generalist model of visual data. Sora is an adaptation of the technology behind DALL·E, OpenAI’s text-to-image model that can create diverse and imaginative images from text prompts.
Some have speculated that Sora was trained on synthetically generated data from Unreal Engine 5 (UE5) from Epic Games, given the similarities with UE5 simulations. UE5 is a state-of-the-art video game engine that can create stunning virtual worlds with realistic lighting and physics. Sora-generated videos don’t have the usual distortion of hands and characters that we generally see on other diffusion models.
Sora is a remarkable achievement in video generation and simulation, which are challenging domains for AI. Video generation requires modeling complex spatiotemporal dynamics, realistic rendering, and semantic coherence. Video simulation requires understanding the rules and physics of the virtual world, as well as the ability to control and manipulate the agents within it. Sora demonstrates that scaling video models is a promising path towards building general-purpose simulators of the physical and digital world, and the entities that live within them. Such simulators could have many applications in entertainment, education, research, and more.
The details:
It uses a diffusion transformer to generate videos from random noise and text prompts.
Sora can edit videos by changing the duration, background, style, etc.
The model can generate videos from scratch, based on text prompts or existing videos.
It can simulate and interact with digital worlds, such as Minecraft.
Sora also can create novel scenarios, such as new biomes, structures, or creatures.
Why it’s important:
Sora is a remarkable achievement in video generation and simulation, which are challenging domains for AI. Sora demonstrates that scaling video models is a promising path towards building general-purpose simulators of the physical and digital world, and the entities that live within them. Such simulators could have many applications in entertainment, education, research, and more.
Google Gemini 1.5: A Breakthrough in Long-Context Understanding
Google has announced an updated version of its next-generation model, Gemini 1.5, which can process up to 1 million tokens of information in one go, across different modalities such as text, images, audio, video, and code. Gemini 1.5 is a significant improvement over Gemini 1.0, which was already a powerful model for natural language understanding and generation. Gemini 1.5 can perform complex tasks such as analyzing, summarizing, translating, and creating content from large amounts of data, with impressive speed and quality.
Gemini 1.5 is based on a Mixture-of-Experts (MoE) architecture, which divides the model into smaller “expert” neural networks that specialize in different tasks and modalities. This allows the model to handle diverse and challenging data, such as silent movies, rare languages, or large codebases, with ease and accuracy. Gemini 1.5 can also perform in-context learning, meaning that it can learn new skills from information given in a long prompt, without needing additional fine-tuning.
The details:
Gemini 1.5 is based on a Mixture-of-Experts (MoE) architecture, which divides the model into smaller “expert” neural networks that specialize in different tasks and modalities.
It can handle data of variable durations, resolutions, and aspect ratios, making it a generalist model of visual data.
Gemini 1.5 can process up to 1 million tokens in production, which means it can take in 1 hour of video, 11 hours of audio, codebases with over 30,000 lines of code, or over 700,000 words in one prompt.
Model can perform highly-sophisticated understanding and reasoning tasks for different modalities, such as identifying scenes in silent movies, translating rare languages, or explaining code.
The updated model can also perform in-context learning, meaning that it can learn new skills from information given in a long prompt, without needing additional fine-tuning.
Gemini 1.5 has undergone extensive ethics and safety tests, and will be available for developers and enterprise customers via AI Studio and Vertex AI.
Demos of long context understanding:
Why it’s important:
Gemini 1.5 is a breakthrough in long-context understanding, which is a key challenge for AI. Long-context understanding enables AI models to process and comprehend large amounts of information, across different domains and formats, and perform useful tasks with it. This opens up new possibilities for people, developers, and enterprises to create, discover, and build using AI. Gemini 1.5 is a step towards achieving Google’s vision of building helpful and responsible AI for everyone.
Chat with RTX: A New Way to Personalize Your AI Chatbot
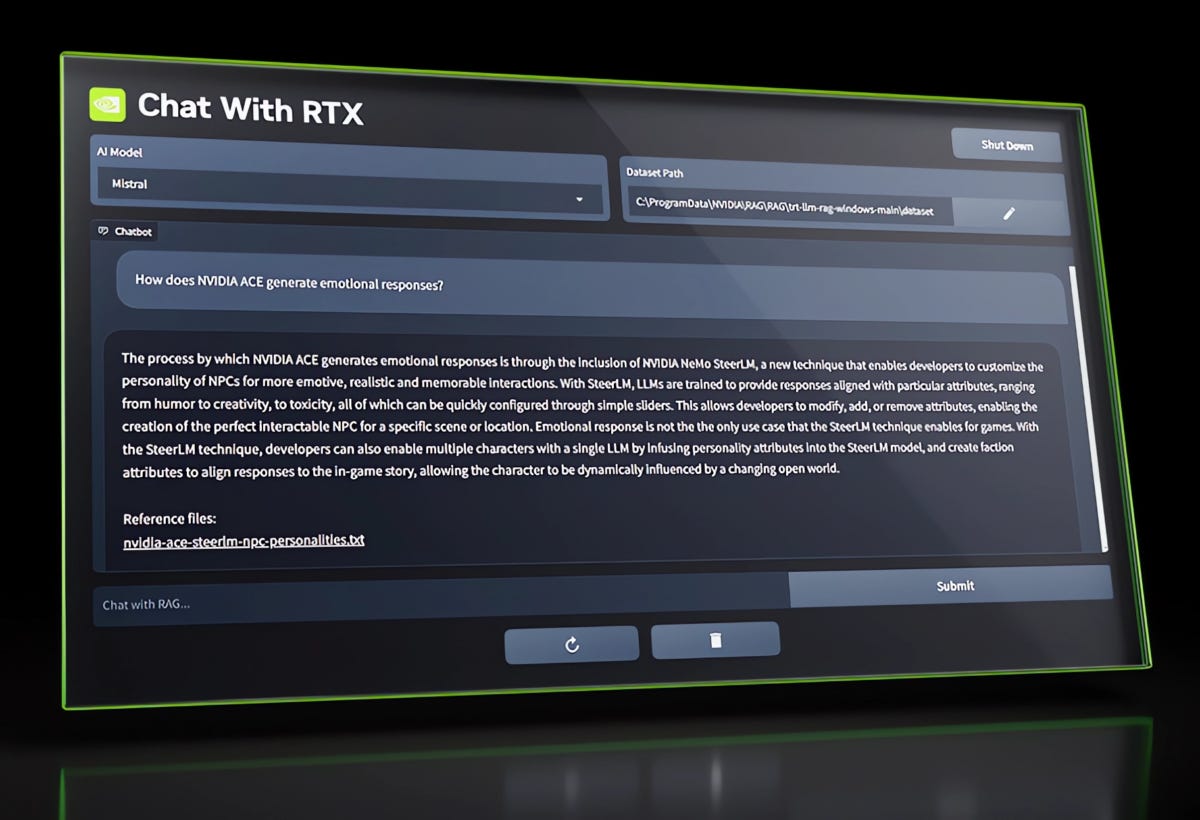
Chatbots are becoming more common and useful in various domains, from customer service to education. But what if you could create your own chatbot that knows the content you care about, such as your notes, documents, videos, or other data? That’s the idea behind Chat with RTX, a new tech demo from NVIDIA that lets you personalize a GPT large language model (LLM) chatbot with your own content, accelerated by a local NVIDIA GeForce RTX 30 Series GPU or higher with at least 8GB of video random access memory, or VRAM.
Chat with RTX uses retrieval-augmented generation (RAG), NVIDIA TensorRT-LLM software and NVIDIA RTX acceleration to bring generative AI capabilities to local, GeForce-powered Windows PCs. Users can quickly, easily connect local files on a PC as a dataset to an open-source LLM like Mistral or Llama 2, enabling queries for quick, contextually relevant answers. For example, one could ask, “What was the restaurant my partner recommended while in Las Vegas?” and Chat with RTX will scan local files the user points it to and provide the answer with context.
The tool supports various file formats, including .txt, .pdf, .doc/.docx and .xml. Users can also include information from YouTube videos and playlists by adding a video URL to Chat with RTX, allowing them to integrate this knowledge into their chatbot for contextual queries. For example, ask for travel recommendations based on content from favorite influencer videos, or get quick tutorials and how-tos based on top educational resources.
The details:
Chat with RTX is a free tech demo that runs locally on Windows RTX PCs and workstations, so the user’s data stays on the device and does not need to be shared with a third party or have an internet connection.
It is built from the TensorRT-LLM RAG developer reference project, available on GitHub, which enables developers to build and deploy their own RAG-based applications for RTX, accelerated by TensorRT-LLM.
The app will soon be compatible with OpenAI’s popular Chat API through a new wrapper, which will allow hundreds of developer projects and applications to run locally on a PC with RTX, instead of in the cloud.
Chat with RTX leverages the power of NVIDIA GeForce RTX 30 Series GPUs or higher with a minimum 8GB of VRAM, which provide next-level AI performance for enhanced creativity, productivity, and gaming.
Why it’s important:
Chat with RTX demonstrates the potential of accelerating LLMs with RTX GPUs, which can enable new and innovative applications of generative AI. By allowing users to personalize their chatbot with their own content, Chat with RTX can help them access information faster, easier, and more securely. Chat with RTX can also inspire developers to create their own custom LLM-based applications with RTX, using the TensorRT-LLM RAG developer reference project or the OpenAI Chat API wrapper. Chat with RTX shows how RTX can empower users and developers to harness the power of AI on their Windows PCs.
OpenAI CEO Sam Altman talks about GPT-5, the next generation of AI chatbot

Sam Altman, the CEO of OpenAI, shared some insights about GPT-5, the upcoming version of the popular AI chatbot ChatGPT, at the World Government Summit. He said that GPT-5 will be smarter, faster, and more multimodal than its predecessor, GPT-4. He also emphasized the importance of general intelligence, which allows the AI models to be better at everything they do. Altman did not reveal the launch date of GPT-5, but some sources suggest that it may be released in spring 2024 under the codename “Gobi”. Meanwhile, OpenAI also announced a new AI model called Sora, which can create videos from text prompts.
How Ukraine Became an AI War Lab for Western Tech Companies

Ukraine is facing a brutal invasion from Russia, but it is also becoming a testing ground for cutting-edge technologies that could shape the future of warfare. One of the companies leading this effort is Palantir, the secretive data-analytics firm that works with intelligence agencies and militaries around the world.
Palantir’s CEO, Alex Karp, visited Kyiv in June 2022 and offered to deploy his company’s software and artificial intelligence to support Ukraine’s defense. He saw it as a way to “defend the West” and to “scare the f-ck out of our enemies.” Ukraine’s government, desperate for any help, agreed to partner with Palantir and other Western tech companies.
The details:
Palantir’s software allows Ukrainian forces to collect, analyze, and visualize massive amounts of data from various sources, such as drones, satellites, sensors, and social media.
Palantir’s AI helps Ukrainian forces to identify patterns, predict enemy movements, and optimize their operations.
Palantir is not the only tech company involved in Ukraine’s war. Other firms, such as Anduril, Shield AI, and Skydweller, are providing drones, robots, and autonomous systems that can operate in contested environments.
Ukraine’s war is also attracting talent and investment from the global tech community. Many Ukrainian engineers and entrepreneurs are developing their own solutions, such as facial-recognition software, cyberdefense tools, and digital platforms for civic engagement.
Why it’s important:
Ukraine’s war is a glimpse into the future of warfare, where software and AI play a crucial role in shaping the battlefield. In conflicts waged with these technologies, where military decisions are likely to be handed off to algorithms, tech companies stand to wield outsize power and influence. This raises ethical, legal, and geopolitical questions that need to be addressed by governments, societies, and the international community.
ChatGPT’s New Memory Feature: A Game-Changer for Language Models

ChatGPT, the popular language model from OpenAI, has recently announced a new feature that will allow it to remember information from past conversations. This feature will enable ChatGPT to deliver more personalized, efficient, and relevant responses, as well as complete tasks more quickly. Users will have full control over what ChatGPT remembers and how their data is used, with options to review, edit, or delete the stored information. The memory feature is a significant step forward in the evolution of ChatGPT and language models in general, as it will make them more helpful, creative, and productive than ever before.
Quick news
AI expert Andrej Karpathy confirms he’s left OpenAI. (link)
ElevenLabs launched “Turn your voice into passive income.” (link)
UMI - a revolutionary framework that teaches robots new skills using (link)
Amazon researchers trained the largest text-to-speech model yet (link)
For daily news from the AI and Tech world follow me on:
Be better with AI
In this section, we will provide you with comprehensive tutorials, practical tips, ingenious tricks, and insightful strategies for effectively employing a diverse range of AI tools.
How to run GPT-4 Vision with the phone camera.
Create and copy a new OpenAI API key from their website.
Paste your Open AI key into the GPT-4 shortcut settings.
On your iPhone, navigate to Settings —> Accessibility —> Touch —> Back Tap —> Double Tab —> GPT-4 Vision shortcut.
You're done! Now you can open the camera and double-tap the back of your phone to get a description of what you see.
Thanks to Alvaro Cintas
Tools
📅 Meetingly - Transform sales calls into actionable insights effortlessly (link)
🎥 Anxiety Simulator - insights into anxiety disorders (link)
✉️ Visme - Create stunning visual designs effortlessly with AI assistance (link)
🗨️ NotesGPT - Transform voice notes into clear and concise action items (link)
📼 OS-Copilot - Towards Generalist Computer Agents with Self-Improvement (link)
We hope you enjoy this newsletter!
Please feel free to share it with your friends and colleagues and follow me on socials.