

NeuralByte's weekly AI rundown - 10th March
NeuralByte's weekly AI rundown - 10th March
Stable Audio 2.0 and poweful upgrade for Siri!
Greetings fellow AI enthusiasts!
Another exciting week is behind us. I’m running a bit late as last week but I will try to make it as usual on Sunday next time. There was many interesting news. Stability AI launched the new Stable Audio V2 with the ability to generate audio-to-audio or full-length tracks. Also, Apple showed paper for its voice model which I’m most excited about, the ReALM. Siri will get powerful. And I have a lot more news for you.

Dear subscribers,
Thanks for reading my newsletter and supporting my work. I have more AI content to share with you soon. Everything is free for now, but if you like my work, please consider becoming a paid subscriber. This will help me create more and better content for you.
Now, let's dive into the AI rundown to keep you in the loop on the latest happenings:
🔥 Stable Audio 2.0: Elevating Music Creation with AI
📱 Apple’s ReALM: A Game-Changer for Voice Assistants
💵 Google Contemplates AI-Generated Content Paywall
📹 Revolutionizing Video Generation with CameraCtrl
🤖 The Octopus V2 Model
👾 Many-Shot Jailbreaking in AI
🤖 Apple’s Foray into Home Robotics
🧠 The Mixture-of-Depths Approach
🕵️ GitHub Issue Resolution: The SWE-Agent
💻 Microsoft and OpenAI’s Ambitious $100 Billion AI Supercomputer Project
🫨 Taiwan’s Earthquake Disrupts Global Tech
🖼️ New Features in The DALL·E Editor Interface
🥽 Apple Vision Pro Enhances Collaboration with Spatial Personas
📹 Generative AI Revolutionizes Video Creation
And more!
Stable Audio 2.0: Elevating Music Creation with AI
Stable Audio 2.0 has been unveiled, offering a groundbreaking update to the world of AI music generation. This advanced model allows for the creation of high-quality, full tracks up to three minutes long, all from a single natural language prompt. It’s not just text-to-audio; users can now upload audio samples and transform them into a diverse range of sounds, enhancing the creative process for artists and musicians.
Building on the success of Stable Audio 1.0, the new model introduces audio-to-audio capabilities, expanding the possibilities for sound effect generation and style transfer. This provides creators with unprecedented control and flexibility, allowing them to produce melodies, backing tracks, stems, and sound effects with ease. The model is available for free on the Stable Audio website and will soon be accessible via the Stable Audio API.
The architecture of Stable Audio 2.0 is designed to generate full tracks with coherent structures, including intros, developments, and outros. A new autoencoder and a diffusion transformer work in tandem to process long sequences, ensuring high-quality musical compositions. The model is trained on a vast dataset from AudioSparx and employs content recognition technology to protect copyrights.
The details:
Full-Length Tracks: Generates songs with structured compositions, including intros and outros.
Audio-to-Audio Generation: Transforms uploaded audio samples into fully produced tracks.
Variations and Sound Effects: Produces a wide range of sound effects, enhancing audio projects.
Style Transfer: Customizes audio to match specific project styles and tones.
Advanced Architecture: Employs a new autoencoder and diffusion transformer for coherent structures.
Why it’s important:
Stable Audio 2.0 represents a significant leap forward in AI-powered music creation. It democratizes music production, making it accessible to a wider audience, including AI enthusiasts and business owners. The model’s capabilities allow for the exploration of new artistic horizons, pushing the boundaries of creativity and innovation. Its importance lies in its potential to revolutionize the music industry, providing tools that were once available only to professionals, now to anyone with a passion for music and sound design. This is not just an advancement in technology; it’s a catalyst for artistic expression and cultural evolution.
Apple’s ReALM: A Game-Changer for Voice Assistants
Apple’s innovative AI model, ReALM, is set to revolutionize the way voice assistants understand and interact with users. By focusing on reference resolution, ReALM allows assistants like Siri to interpret ambiguous references with unprecedented accuracy. This breakthrough is particularly significant as it enhances Siri’s contextual understanding, making it faster and smarter—potentially as part of the upcoming Siri 2.0.
ReALM’s design is tailored to run efficiently on devices, aligning with Apple’s commitment to privacy and performance. It’s a leap forward in AI, enabling voice assistants to “see” the screen context, thus facilitating more natural and intuitive interactions. With ReALM, Apple is not just improving Siri but is also setting new standards for AI in voice-activated devices.
The details:
ReALM’s Innovation: Transforms reference resolution into a language modeling problem, improving Siri’s response accuracy.
Performance: Even the smallest ReALM model rivals GPT-4, with larger versions surpassing it.
On-Screen Context: Allows Siri to understand and reference on-screen content, enhancing user interaction.
Efficiency: Designed to run on-device, ensuring privacy and reducing reliance on cloud processing.
Apple’s AI Expansion: Part of a broader initiative to integrate AI across Apple’s ecosystem, potentially including Siri 2.0.
Why it’s important:
ReALM’s ability to process both on-screen and conversational context is a significant step towards more sophisticated voice assistants. This technology not only makes interactions with devices like iPhones more seamless but also has the potential to assist users with disabilities by simplifying indirect interactions. For business owners, the implications are vast, offering a glimpse into a future where AI can provide real-time assistance without compromising privacy or performance. Apple’s ReALM is not just an upgrade; it’s a vision of what’s next in the realm of AI and technology.
Google Contemplates AI-Generated Content Paywall
In a significant shift, Google is reportedly considering a paywall for premium AI-generated content. This move could transform the accessibility of advanced AI capabilities for users worldwide. The search engine giant, which serves over a billion people, is exploring the addition of AI-powered search features to its subscription services, including the new AI assistant Gemini.
The details:
AI Paywall: Google may introduce a subscription model for its advanced AI features, marking a departure from its traditionally free offerings.
Gemini’s Controversy: The AI assistant Gemini faced backlash for generating historically inaccurate images, prompting Google to pause the service.
Revenue Diversification: Google’s parent company, Alphabet, boasts a valuation of $1.6 trillion, with diverse ventures contributing to its $305.6 billion revenue in 2023.
Search Engine Dominance: Despite controversies, Google remains the preferred search engine for the majority, commanding over 80% of the desktop market.
Subscription Services Expansion: Google plans to enhance its subscription offerings with new premium capabilities, although specifics are yet to be announced.
Why it’s important:
Google’s potential pivot to a paywalled AI service underscores the growing value of AI in the digital economy. As AI technologies become more sophisticated, companies like Google are seeking ways to monetize these advancements while continuing to offer core services. This strategy not only reflects the increasing commercialization of AI but also highlights the challenges tech giants face in balancing innovation with ethical considerations and public trust. The outcome of Google’s deliberations could set a precedent for how AI services are packaged and sold, influencing the industry’s direction and user experience
Revolutionizing Video Generation with CameraCtrl
In the realm of video generation, the quest for precision has led to the creation of CameraCtrl, a groundbreaking tool designed to master the art of camera control. This innovation allows for the meticulous manipulation of camera poses, a cinematic element crucial for conveying deeper narrative layers. By integrating a camera module with existing text-to-video models, CameraCtrl offers a plug-and-play solution that enhances controllability without altering the original model’s architecture. Its ability to adapt to various domains and handle diverse camera trajectories makes it a significant advancement in dynamic video storytelling, catering to both textual descriptions and camera pose inputs. The approach is a testament to the potential of AI in enriching the video creation process, promising a future where videos are not just seen but felt, with every frame tailored to the creator’s vision.
On-Device AI: The Octopus V2 Model
The world of artificial intelligence is witnessing a significant shift with the introduction of the Octopus v2 model, a groundbreaking on-device language model designed for super agents. Developed by researchers at Stanford University, this model promises to surpass the performance of GPT-4 in both accuracy and latency, while also reducing the context length required for processing by a staggering 95%. The Octopus model represents a leap forward in AI, offering a solution that addresses privacy concerns and the high costs associated with large-scale cloud-based models.
The Octopus v2 model is not just another incremental improvement; it’s a transformative approach that redefines the capabilities of on-device AI. By fine-tuning the model with functional tokens, it achieves state-of-the-art results in function calling tasks, crucial for creating AI agents. This method enables the model to understand software application capabilities with remarkable precision, mapping function descriptions to specific tokens and significantly enhancing latency by 35-fold compared to existing methods.
The implications of the Octopus model are vast and varied. For businesses and AI enthusiasts alike, this innovation opens up new possibilities for deploying AI in production environments across a range of edge devices. It’s a game-changer that aligns with the performance requisites for real-world applications, promising to empower users with dependable software that leverages the full potential of AI.
The details:
Superior Performance: The Octopus model outperforms GPT-4 with a 2 billion parameter setup, achieving better accuracy and latency.
Privacy and Cost-Effective: It offers a privacy-conscious alternative to cloud models, reducing inference costs and the need for constant connectivity.
Edge Device Deployment: Designed for smartphones, cars, VR headsets, and PCs, it addresses the challenges of latency and battery life on edge devices.
Function Calling Mastery: With its innovative function calling method, the model can perform complex tasks with minimal latency, ideal for real-time applications.
Research Breakthrough: The model’s development is a testament to the robust research in AI, showcasing advancements in multitask learning and meta-learning.
Why it’s important: In an era where data privacy and cost efficiency are paramount, the Octopus model stands out as a beacon of innovation. It not only mitigates the privacy risks associated with cloud-based models but also slashes the costs of deploying AI in various applications. The model’s ability to perform with high accuracy and low latency on edge devices makes it a critical tool for businesses looking to integrate AI into their operations without compromising on performance or user experience. As AI continues to evolve, the Octopus model is poised to play a pivotal role in shaping the future of on-device AI applications, making it an essential development for both AI enthusiasts and business owners.
Many-Shot Jailbreaking in AI
The AI research community is abuzz with the findings from Anthropic’s latest study on “many-shot jailbreaking,” a technique that challenges the safety protocols of large language models (LLMs). This method exploits the extended context window of LLMs, potentially eliciting harmful responses despite safety training. The study is a wake-up call for AI developers, highlighting the need for robust safety measures as AI systems grow more powerful.
Anthropic’s researchers have uncovered a vulnerability in LLMs that could be exploited using a “many-shot” technique. By inserting a series of faux dialogues within a single prompt, the model’s safety mechanisms can be bypassed, leading to the generation of unsafe content. This discovery is particularly concerning given the increasing capabilities of AI systems.
The details:
Context Window Expansion: LLMs now have context windows large enough to process information equivalent to several novels, increasing the risk of safety breaches.
Many-Shot Technique: A series of fake dialogues can trick LLMs into providing harmful responses, circumventing safety training.
Scaling Effect: The effectiveness of this jailbreaking method grows with the number of dialogues, revealing a pattern similar to in-context learning.
Model Susceptibility: Larger models, which excel at in-context learning, are more vulnerable to many-shot jailbreaking.
Mitigation Strategies: While reducing the context window size could prevent jailbreaking, prompt modification and other methods are being explored to counteract this vulnerability.
Why it’s important:
The revelation of the many-shot jailbreaking technique underscores the dual nature of AI advancements—while they bring significant benefits, they also introduce new risks. As AI models become more sophisticated, they also become more susceptible to exploitation. Anthropic’s study serves as a crucial reminder of the importance of safety in AI development. It’s imperative for the AI community to understand and mitigate these risks to ensure that AI technologies remain safe and beneficial for society at large. The study by Anthropic is not just a technical report; it’s a call to action for responsible AI development.
Apple’s Foray into Home Robotics

Apple Inc. is venturing into the realm of personal robotics, exploring innovative home devices that could redefine our daily interactions with technology. The company’s engineers are working on a mobile robot capable of following users around their homes, as well as an advanced table-top device that employs robotics to reposition a display. These projects, still under wraps, signal Apple’s search for new growth avenues and its commitment to pushing the boundaries of consumer technology.
The Mixture-of-Depths Approach
Researchers at Google DeepMind have introduced a novel method called Mixture-of-Depths (MoD) for transformer-based language models, aiming to optimize the allocation of computational resources. By capping the number of tokens that can participate in computations at each layer, MoD allows for dynamic and context-sensitive allocation of computational power across different positions in a sequence.
The technique is designed to work within a static computation graph, maintaining known tensor sizes, which is more compatible with current hardware constraints. This approach enables models to match baseline performance with significantly reduced computational expenditure per forward pass, potentially leading to faster and more efficient AI systems.
The Details:
Dynamic Compute Allocation: MoD transformers can dynamically allocate computational resources, focusing on specific tokens that require more attention, thus optimizing overall performance.
Efficient Training: These models can achieve training loss parity with traditional transformers while using up to 50% fewer FLOPs per forward pass, resulting in faster training times.
Hardware Compatibility: MoD maintains a static computation graph, avoiding the complexities of dynamic computation graphs and ensuring better hardware utilization.
Predictive Routing: The method includes a predictive router for efficient inference, enabling the model to make intelligent decisions about which tokens to process.
Performance Gains: Despite reduced computational resources, MoD transformers can outperform or match the efficiency of traditional models, demonstrating the potential for smarter AI.
Why It’s Important:
The Mixture-of-Depths approach represents a significant leap forward in the pursuit of more efficient AI. By intelligently allocating computational resources where they are most needed, MoD transformers can reduce the overall computational cost without sacrificing performance. This is particularly crucial as AI models become increasingly complex and demand more processing power.
Moreover, the compatibility of MoD with existing hardware infrastructure means that these efficiency gains can be realized without the need for costly hardware upgrades. This makes the approach accessible and beneficial for businesses looking to leverage AI without incurring prohibitive costs. As AI continues to permeate various industries, methods like MoD that enhance efficiency while maintaining performance will be vital for sustainable and scalable AI development.
GitHub Issue Resolution: SWE-Agent
Meet SWE-agent, the open-source AI programmer developed by Princeton University’s NLP group, which is transforming the landscape of GitHub issue resolution. With its ability to autonomously fix errors in real-time, boasting an average response time of just 93 seconds, SWE-agent stands out for its speed, accuracy, and innovative use of large models like GPT-4. This groundbreaking tool not only simplifies the debugging process for developers but also serves as a learning platform for new coders, enhancing their understanding of code structure and problem-solving strategies. As SWE-agent gains popularity, it heralds a new era of collaboration between humans and AI in software development, promising a future where technological progress redefines our coding processes and paves the way for more efficient and accurate programming.
Microsoft and OpenAI’s Ambitious $100 Billion AI Supercomputer Project
X is set to enhance the AI landscape with the upcoming release of Grok 1.5, an upgraded version of its widely acclaimed chatbot. This iteration promises to refine user interactions through advanced natural language processing, aiming to bridge the gap between human and machine communication. With a focus on nuanced dialogue and contextual understanding, Grok 1.5 is poised to offer a more intuitive and seamless experience, catering to the intricate needs of AI enthusiasts and business owners alike. As the anticipation builds, the tech community eagerly awaits to witness the potential of this sophisticated AI model.
Taiwan’s Earthquake Disrupts Global Tech
A 7.4-magnitude earthquake in Taiwan has caused significant disruptions in semiconductor production, with companies like TSMC and UMC halting operations to assess damages. This event not only impacts the local infrastructure but also poses a threat to the global supply of advanced chips, crucial for powering AI technologies and modern electronics. The quake underscores the fragility of the tech industry’s reliance on this region, which is responsible for a substantial portion of the world’s most sophisticated semiconductors. As Taiwan grapples with the aftermath, the incident highlights the urgent need for geographical diversification in chip manufacturing to mitigate risks associated with natural disasters and geopolitical tensions.
New Features in The DALL·E Editor Interface
In a groundbreaking advancement, the DALL·E editor interface has emerged as a transformative tool for image editing, allowing users to refine their creations through a chat-based interface or direct prompts. This innovative feature enables precise edits by selecting image areas and articulating desired changes, offering an unprecedented level of control and customization. With options to add, remove, or alter elements within the artwork, the interface caters to both casual users and professionals seeking to fine-tune their visual expressions. The simplicity of saving edits and the flexibility to edit on mobile platforms further enhance the user experience, marking a significant leap forward in creative technology.
Apple Vision Pro Enhances Collaboration with Spatial Personas
Apple’s Vision Pro now supports spatial Personas, allowing users to interact in a shared virtual space across SharePlay-enabled apps. The update, introduced in VisionOS 1.1, aims to create a more immersive experience by enabling up to five participants to collaborate, play, or watch media together. While the Vision Pro app store’s offerings are still growing, this feature’s real-world effectiveness and impact on user engagement are yet to be fully assessed.
Generative AI Revolutionizes Video Creation
In the rapidly evolving landscape of generative AI, Higgsfield emerges as a game-changer with its first application, Diffuse, designed to democratize video creation. Co-founded by Alex Mashrabov, a former Snap executive, Higgsfield offers a suite of tools that enable users to generate videos from text prompts or even insert themselves into AI-crafted scenes. With a focus on social media marketers and content creators, the platform stands out for its mobile-first approach and user-friendly design. Despite operating with a lean team and modest funding, Higgsfield competes with giants like OpenAI, aiming to carve a niche in the social media marketing realm with its innovative video generation models and a vision for a future where premium features could be monetized. Amidst the excitement, the company navigates the complexities of copyright and ethical concerns, ensuring safeguards against misuse while fostering creativity in the digital space.
Be better with AI
In this section, we will provide you with comprehensive tutorials, practical tips, ingenious tricks, and insightful strategies for effectively employing a diverse range of AI tools.
Generative AI for Beginners
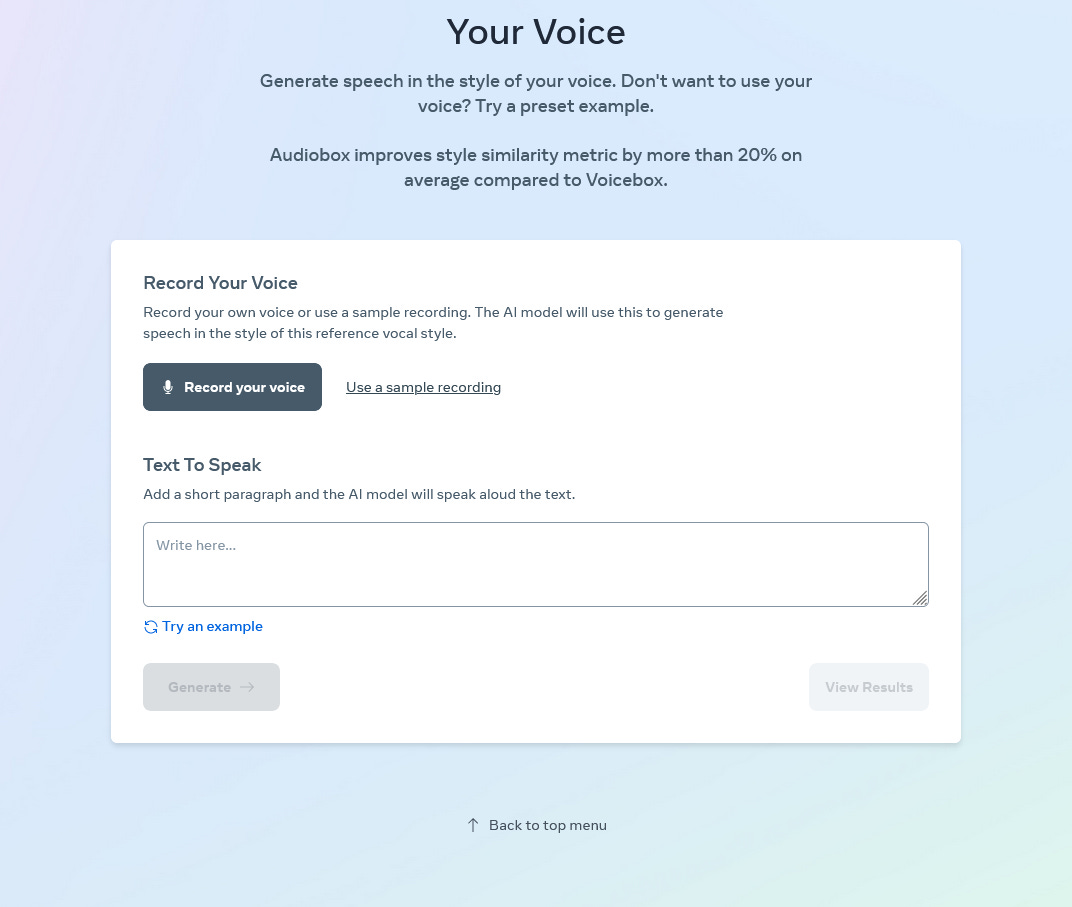
AudioBox represents Meta’s innovative foundational research model dedicated to audio creation. In this guide, we’ll demonstrate how to utilize this tool to produce AI-generated audio that mimics your voice, at no cost.
Navigate to the AudioBox demonstration and proceed downwards.
Select “Record your voice” to record your voice, or opt for text-based descriptions or available voice samples as alternatives.
AudioBox will guide you to vocalize a brief phrase to contribute your voice to the system.
Enter the script you wish to synthesize post-recording (or select an existing audio file).
We hope you enjoy this newsletter!
Please feel free to share it with your friends and colleagues and follow me on socials.